L'Odyssée des Réseaux de Neurones
"L'intelligence artificielle n'est pas une magie, c'est une imitation mathématique de la nature."
Le Rêve Biologique (1943 - 1957)
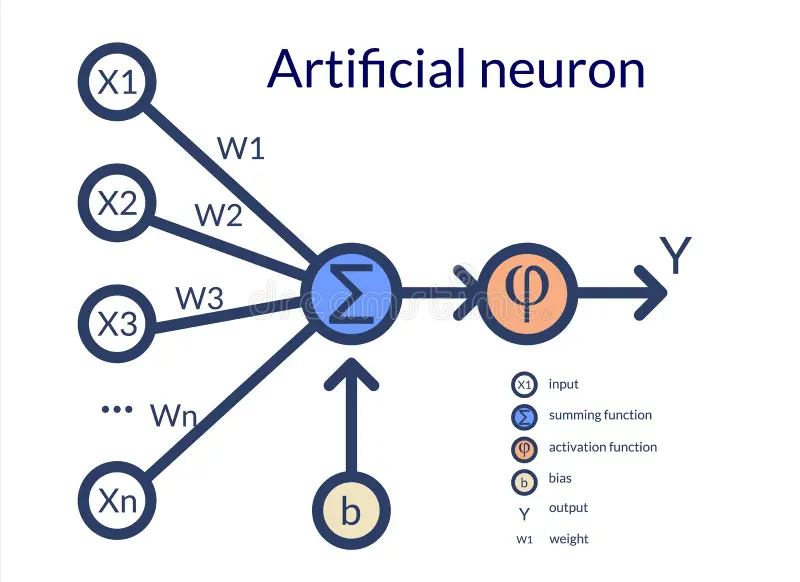
Tout commence par une ambition folle : reproduire le cerveau humain. Dès 1943, McCulloch et Pitts posent la première pierre en modélisant un neurone artificiel sous forme mathématique. Mais c'est en 1957 que Frank Rosenblatt donne vie à ce concept avec le Perceptron.
Imaginez une machine capable d'apprendre par l'expérience, inspirée par les connexions synaptiques biologiques. Le principe est simple : des entrées, des poids (l'importance de l'information) et une somme. Si la somme dépasse un seuil, le neurone s'active.
L'Hiver de l'IA (1969)
L'euphorie retombe brutalement. En 1969, Minsky et Papert publient une critique dévastatrice. Ils prouvent mathématiquement que le Perceptron simple est incapable de résoudre des problèmes non-linéaires basiques, comme le fameux problème XOR (le "Ou exclusif").
Si les données ne sont pas séparables par une simple ligne droite, le Perceptron échoue. Cette limite plonge la recherche dans un "Hiver de l'IA" qui durera plus de dix ans.

La Renaissance et le Deep Learning (1986)
Le dégel arrive grâce à une idée brillante : empiler les couches. En 1986, Rumelhart, Hinton et Williams popularisent l'algorithme de rétropropagation du gradient. C'est la clé qui permet d'entraîner des réseaux profonds.
Le réseau peut enfin apprendre de ses erreurs, ajuster ses poids couche par couche et tordre l'espace pour résoudre des problèmes complexes. C'est la naissance véritable du Deep Learning.
L'Ère du Pionneering (1990 - 2005)
Durant ces années, les réseaux de neurones commencent à quitter les laboratoires. Yann LeCun développe les Convolutional Neural Networks (CNN) en 1998, inspirés par la structure du cortex visuel. Ces réseaux révolutionnent la reconnaissance d'images et traitent avec succès des millions de paramètres.
Les limitations computationnelles restent cependant un défi majeur. Les ordinateurs de l'époque, même puissants, peinent à entraîner des réseaux vraiment profonds. Pourtant, des succès émergent : reconnaissance de chiffres manuscrits, premières applications industrielles, et la preuve que le Deep Learning fonctionne réellement.
La Révolution des GPUs (2006 - 2012)
Le tournant arrive avec une technologie inattendue : les cartes graphiques. Ces processeurs, initialement conçus pour les jeux vidéo, se révèlent exceptionnels pour les calculs parallèles massifs que le Deep Learning demande.
En 2006, Geoffrey Hinton montre comment entraîner efficacement des réseaux profonds. En 2012, une équipe dirigée par Alex Krizhevsky remporte la compétition ImageNet avec un CNN profond : AlexNet, réduisant l'erreur de classification de 26 % à 15 % en une seule année. C'est la preuve que l'ère du Deep Learning est arrivée.
L'Explosion du Deep Learning (2012 - 2017)
Après AlexNet, c'est l'explosion. Des architectures plus profondes et plus sophistiquées émergent : VGGNet, ResNet, Inception. Les chercheurs découvrent que plus les réseaux sont profonds, mieux ils apprennent (à condition d'avoir assez de données).
Parallèlement, Yoshua Bengio popularise les réseaux de neurones récurrents (RNN) et les LSTM (Long Short-Term Memory) pour traiter les séquences. Ces architectures fuient le problème de la disparition du gradient et permettent de traiter le langage naturel, la traduction automatique et la prédiction de séries temporelles.
Cette période transforme l'IA de "jouet académique" en technologie industrielle : reconnaissance faciale, traduction automatique, assistants vocaux deviennent réalité.
L'Ère de l'Attention et des Transformateurs (2017 - 2020)
Un papier révolutionnaire intitulé "Attention is All You Need" paraît en 2017. Les chercheurs de Google proposent l'architecture Transformer, basée sur un mécanisme d'attention qui permet aux réseaux de se concentrer sur les parties les plus pertinentes des données.
Contrairement aux RNN qui traitent les données séquentiellement, les Transformateurs traitent tout en parallèle. C'est exponentiellement plus rapide et plus scalable. Cette architecture devient la fondation des futurs modèles de langage géants.
Des modèles comme BERT (2018) et GPT-2 (2019) commencent à montrer des capacités remarquables de compréhension et de génération de texte. L'IA commence enfin à vraiment "comprendre" le langage.
L'Ère des Modèles Géants (2020 - Aujourd'hui)
Avec des GPU toujours plus puissants et des quantités massives de données, une nouvelle tendance émerge : les modèles de langage de plus en plus grands. GPT-3 (2020) avec 175 milliards de paramètres étonne le monde. Des tâches qui semblaient impossibles deviennent triviales : traduction, rédaction, programmation, raisonnement logique.
En novembre 2022, ChatGPT est lancé et devient l'application grand public la plus adoptée de l'histoire. Soudainement, tout le monde comprend le potentiel de l'IA. Les modèles de vision (DALL-E, Midjourney) génèrent des images photo-réalistes à partir de simples descriptions textuelles.
Les avancées s'accélèrent : GPT-4, Claude, Gemini poussent les limites encore plus loin. L'IA générative devient omniprésente dans l'industrie, transformant l'éducation, la médecine, l'art, la programmation et presque chaque domaine de la connaissance humaine.
Ce que les pionniers de 1943 rêvaient de créer n'était que l'ombre de ce qu'on réalise aujourd'hui : une intelligence artificielle capable de résoudre des problèmes complexes, de créer du contenu, et de collaborer avec les humains.